Jak postupně píšu Trailblazer a používám jednotlivé moduly, přišla řada i na proceduru pro kreslení obrázků. A tak jsem si říkal, že bych zde mohl uveřejnit příklad, jak lze postupovat při postupné akceleraci nějaké procedury. A procedura pro kreslení obrázků se přímo nabízí.
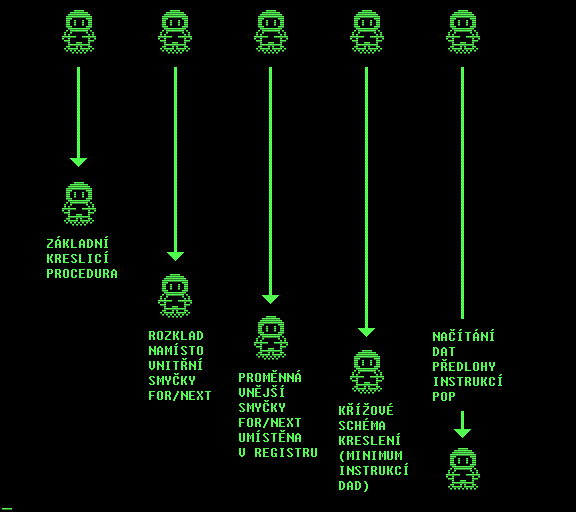
Jako výchozí model, ke kterému budu vztahovat následné časové úspory, si zvolím nějaký jednoduchý algoritmus kreslení obrázku. Není úmyslně roztahaný, aby ty úspory vypadaly pěkně. Prostě je to doslovný překlad toho, jak pomocí dvou smyček, pro osu X a osu Y beru grafická data předlohy a kopíruji je do videoram. Následují čtyři postupné evoluční kroky, kterými se budu snažit zmenšit počet taktů CPU, nutných pro vykreslení postavičky o rozměru 18×23 pixelů, tedy 3 „videobajty“ na šířku a 23 mikrořádků na výšku.
Výchozí neoptimalizovaná procedura kreslení
Neoptimalizovaná procedura trvá 3986 taktů CPU. Jako první úsporné opatření se nabízí vynechání vnitřní smyčky FOR/NEXT pro data v ose X a její nahrazení trojnásobným opsáním těla původního cyklu. Nutno říci, že je to jedna ze dvou největších dosažitelných úspor.
Po této dietní kůře se dostáváme na 2678 taktů CPU, což představuje 67% původní doby. Co ale teď? Zaměříme se na to, co se stále dokola vykonává, a přitom to není nositelem požadované funkce. Instrukce PUSH PSW a POP PSW na začátku a na konci těla cyklu. Pokud vyhradíme proměnné cyklu její vlastní registr, který nebude používán pro žádné další účely, mohlo by to něco přinést. A taky že jo. Ovšem zadarmo to není. Musíme zapojit do hry registr SP a s tím spojenou režii pro uschování a obnovení jeho hodnoty před a po proceduře.
Tato optimalizace přinesla zkrácení na 2252 taktů CPU, tedy 56% doby původní neoptimalizované procedury. Co je nyní nejdelšího na použitém algoritmu kreslení? No přece nejdelší instrukce (z hlediska počtu taktů). A to je instrukce DAD. Ano, je tam v těle cyklu jen jednou jedinkrát, ale i to může být předmětem redukční diety. Jak s ní ven? No to nepůjde. Musí tam být. Ovšem ne tak často, ne na konci každého mikrořádku. Pokud vhodně přeskládáme obrazová data předlohy, můžeme kreslit obrázek v tomto pořadí:
- 0. mikrořádek zleva doprava
- 4. mikrořádek zprava doleva
- 8. mikroádek zleva doprava
- 12. mikrořádek zprava doleva
- a tak dále..
Přínosem je, že k výpočtu adresy nového mikrořádku nepotřebuji instrukci DAD o délce 10 taktů ale pouze instrukci INR H o délce 5 taktů. On totiž posun adresy ve videoram o hodnotu 256 (to je to INR H) je právě posunem o 4 mikrořádky níže. A jen jednou po několika mikrořádcích se instrukcí DAD vrátím do levého horního rohu obrázku, ovšem o jeden mikrořádek níže než minule. Po přesně čtyřech průchodech obrázkem je obrázek hotov. Výsledné řešení uvádí následující Optimalizace č.3:
Tyto úpravy zkrátily proceduru kreslení obrázku na 1944 taktů CPU, což je 49% doby kreslení původní procedury. Ovšem nárůst bajtové délky kódu je značný. Poslední optimalizace přinese nejen mírné zkrácení ale i druhou největší redukci doby, nutné pro vykreslení obrázku. A čím to? Pro přenos dat využijeme nikoliv instrukce přenášející jeden bajt (MOV, LDAX, STAX) ale takové instrukce, které přenášejí najednou bajty dva. Takové instrukce jsou z rodiny instrukcí pro práci se zásobníkem (POP, PUSH) a mají tu výhodu, že na přenos těch dvou bajtů musí CPU načíst pouze jednou operační kód instrukce. Do videoram takto zapisovat sice obecně lze (instrukcí PUSH – dělá to tak BIOS PMD 85-2 u procedury CLS), ale v našem případě by to kolidovalo s lichou šířkou obrázku. Takže budeme ekvivalentně pomocí instrukce POP načítat data předlohy obrázku. Registr SP jsme už stejně použili v předchozím pokusu, takže navýšení režie pro jeho obsluhu už bylo zaplaceno.
Zastavili jsme se na 1457 taktech CPU, což obnáší 37% doby původní neoptimalizované kreslicí procedury, která těch taktů potřebovala 3986. Tak tedy shrnutí. Obecně platí pro časové optimalizace kódu následující pravidla.
- Režie smyček typu FOR/NEXT (tedy různé PUSH, POP, DCR, JNZ) musí být z časového pohledu zanedbatelná vůči době trvání vlastního těla cyklu. Když by bylo neúnosné opisovat tělo cyklu například 100x, opíšu tělo cyklu například 4x a nechám cyklus opakovat 25x. Už toto přináší úspory někdy v desítkách procent (viz grafické procedury v BIOSu PMD 85-2).
- Pro proměnné, se kterými se často pracuje (například zmíněné proměnné cyklu) používat ty registry CPU, které nebudou použity pro jiné činnosti.
- Vybrat pro požadovanou funkci instrukce s minimálním potřebným počtem taktů.
- Přenosy velkých objemů dat (typicky grafika) realizovat za pomoci instrukcí POP/PUSH/XTHL.
Výše uvedené bude ovšem v praxi vykoupeno větší délkou programu. Je to něco za něco. Máte na výběr. Ale zpět k našemu příkladu. Graficky znázorňuje poměr rychlostí vykreslování následující obrázek. Vlevo je postavička, k jejímuž „pohybu“ je použita původní, nejpomalejší procedura kreslení, vpravo pak postavička s nejrychlejší kreslicí procedurou. Postavičky startují nahoře a pohybují se směrem dolů. První postavička, která dosáhne dolního konce obrazovky, závod ukončí.
Pokud byste chtěli vidět vlastní závod postaviček, můžete si do emulátoru PMD 85 od RM TEAMu nahrát následující program, používající multitasking pro pět uvedených kreslicích procedur.